
| Objectives: To introduce practices for sound software design. |
In this chapter we will focus on how to design a program and what can be done to improve its reliability.
You are the New Products Manager for a company and you are in charge of design and development of new products.
What would be your first task in bringing a new product to the marketplace? In fact, there are two unexpected first
steps in the design process, both related to each other. The first step is to conduct a market survey. Is
there a market for your product? What kind of response or queries does your advertisement campaign generate? What
features are potential customers looking for? When you see glossy ads for a new instrument or software package
did you know that many times you are looking at mock-ups? Smart companies would not expend costly design and development
efforts if there was no market for their product. So instead of actually developing the finished product they present
cardboard mock-ups or dummies for advertising purposes. The screens you see for a new software package may be just
illustrations made up from a graphic presentation software. But the purpose of this fake shell is more than skin
deep. It allows the company to define what the new product should look like as well as to generate interest and
feedback from potential customers.
The second unexpected step to be undertaken is the preparation of the User's Manual. Some companies create the user's manual just prior to shipping the product out the door. This shows poor design. Like the mock-up and fake screens, the user's manual defines what the product should look like and how it is expected to function, operate, and be operated. The user's manual defines the specifications for the product and how the user is expected to interact with the product. This gives the design engineers and software writers a complete description of their final goals. The development of the product must follow from the specifications defined in the user's manual. This is top-down design.
Similarly, when you are embarking on a design exercise the first step is to layout the specifications. What are the requirements? What should the final product look like? How does it function? How does one use it? What are the limitations?
New products are not technology driven. They are demand driven. That is, the market place dictates the success of a product. The product is not driven by the technology. By the same token, people should not have to learn how to use a new machine. Instead, the machine should be engineered to suite the way people function.
In summary, the initial planning and design stage of any product development is the most crucial. Full specifications and the user interface must be defined in advance. This design process embodies the concept of top-down design.
Structured programming concepts are used to prevent haphazard program branching resulting in what we call spaghetti code, that is, resembling a bowl of spaghetti. Control structures define how programming code must be organized, especially pertaining to branching. The first rule of a control structure is that there must be only one entry point and only one exit point for each structure. Flow diagrams or charts are used to graphically illustrate these structures. There are four clearly defined control structures as follows:
The simple sequence control block is the most primitive structure. All programs, sub-programs and modules and all other control structures have this basic structure. The basic rule of one entry and one exit applies. A larger program consists of a linear chain of many separate processes.
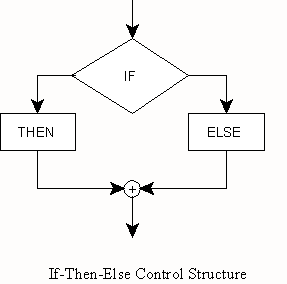
The If-Then-Else control structure is the decision making process. A condition is tested from which there can be only two outcomes, true or false. Therefore, there can be only one of two processes performed depending on the outcome. Program flow after both processes resumes at the same junction point. In some situations, there is only one significant process and the other process is non-existent, i.e. program control flows through to the junction and on to the next process.
The Do-While and Repeat-Until control structures are variations of the same loop structure. The BASIC FOR-NEXT loop or the Fortran DO-CONTINUE loop are forms of the Do-While structure. In the Repeat-Until block, a process is performed followed by a test to determine if the loop must be repeated. In the Do-While block, the test for loop repetition is conducted before the first iteration of the process is performed.

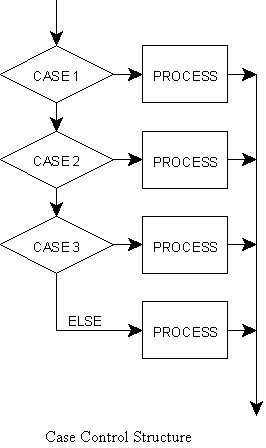
The case control structure is used in situations where there are multiple options of a single variable. The variable may have a number of different possibilities and for each case a different process is called. However, all processes must resume at a common junction in order to fulfill the one entry/one exit rule. Even though the case control structure may look like multiple If-Then-Else structures, many languages support the case statement as a separate structure.
It has been demonstrated by past programming experiences that any decision making process within a programming framework can be formulated using the four structures above. A complex program is created by considering the program to be a single sequence block. This process is broken down into sub-processes where each process can be replaced by any one of the four control structures. In other words, a structure can be nested within the process block of another structure.
Novice programmers are often tempted to begin programming at the lowest level of coding. This is known as the bottom-up approach. This can occur for two reasons. Firstly, the programmer is likely to begin with something he or she is more familiar and confident with. Secondly, the programmer may not have fully formulated a complete picture of the project. He or she hopes that the picture will become clearer as the project progresses. This can lead to many severe inconsistencies at a later stage. Subroutines coded at an earlier stage may have had incomplete specifications or may no longer be compatible with newer requirements. Worst of all the specifications keep on changing.
Top-down approach starts with the overall view, the big picture. It prevents you from getting bogged down with too much details. When "you cannot see the forest because of the trees", you run the risk of losing your sense of direction and your objectives. With top-down approach, you begin with the whole picture, the main program. This is divided into smaller tasks. Each task is further divided into smaller and smaller subtasks until each subtask is minimal, clearly defined and manageable.
Writing code is the easy part. Defining the subtasks and their specifications take more time and effort. Learn to become a project manager. Writing code is the last thing you want to do.
We have all experienced software failures and computer bugs. Is this an expected phenomenon? What can you do to ensure that the code you write is bug free? Past experiences from huge software projects have revealed some interesting observations. From work done on previous projects with the New York Times, they have found that as the number of lines of code in a program increases, the time to completion of the project grows exponentially. Secondly, adding more programmers to the project only helps to a certain point beyond which more programmers actually hinder progress of the project. The number of software bugs encountered also grew exponentially severly increasing the time spent debugging the project. Theoretically, you may have a project that is so gigantic that it is impossible to complete, or results in a product that has not been fully tested and is riddled with bugs. Perhaps this is the state many software packages are at today. Have you noticed how often you are required to purchase new revisions of a program that promises to fix past bugs and then present a new set of bugs?
The key to reliable program begins with top-down design and modular programming. Top-down design produces consistent, coherent and well integrated packages. Modularity produces code that is manageable and reusable. When you break a task down to the lowest possible level, not only are you able to define exact specifications and restrictions on its performance and behavior but also it becomes possible to fully test this behavior independent of other parts of the program. That is, testing now becomes manageable. For example, let us assume that a subroutine to divide two 8-bit integers is required. It may be acceptable to restrict its applications to positive, non-zero values no larger than 255 as long as all users are fully aware of the limitations. But if used without restriction this routine could generate a software bug if it were required to divide by zero.
Here are basic rules for creating reliable code:
For many of us, writing project reports is a very painful task. But as the saying goes, "The job's not over until the paperwork is done!" A good, lucid report is an important part of sound engineering and the task becomes easier with practice. We will try to make this task easier for you by firstly providing some tips for a good report. Secondly, an outline of what is to be expected will be presented.
A typical report should follow the format of a thesis report and should contain the following sections:
Sample Report (Under construction)
Please note that the content of this report is fictional and to be used for illustrative purposes only.
Stacks are very important features of digital computers. A stack can be viewed as a buffer or a queue and is usually implemented in hardware, hence called a hardware stack. When the MCU does not provide a hardware stack, the equivalent function of a stack can be implemented using software.
Before looking at the operation and usage of a stack, let us examine buffers and queues in general. There are two types of buffers. The first is called a First-In/First-Out buffer or FIFO. This type of buffer is commonly encountered in daily life such as a queue at the check-out counter. The first customer in line is the first to be served, usually. The second type of buffer is the Last-In/First-Out buffer or LIFO (same as FILO, first-in/last-out). A good example of a LIFO buffer is the stack of plates in the cafeteria where the last plate placed on the stack is the first to be removed. A computer stack is a LIFO buffer.
Implementation of a stack requires two mechanisms. It requires a storage area or buffer and a pointer or register indicating the location of the top or last item on the stack. The storage or buffer is usually implemented using locations from available memory. In special high speed systems, dedicated hardware registers may be used. The stack pointer (SP) is a hardware register which usually points to the next free location on the stack. The index register can also be used to manipulate data on the stack.
There are two basic stack operations called push and pull (also called pop). When information is pushed onto the stack the SP is automatically updated to indicate the new top of the stack. Information is retrieved in the reverse order using the pull operation and the SP is updated accordingly.
On the HCS08 and HC11, there are only 256 bytes of read/write memory from address $00 to $FF available for programming use. The programmer judiciously uses this memory area for both program variables as well as the stack. Since the SP is decremented on a push instruction, the SP should be initialized to $FF before performing any stack operations. This is accomplished by the reset stack pointer instruction RSP on the HCS08. As information is pushed onto the stack the SP will be decremented and the stack will grow towards lower addresses of memory. Care must be taken to ensure that the stack never collides with variable storage. Should this occur the program will most likely crash!
What is the stack useful for? In fact, there are a number of uses of the stack which assist in the smooth running of modular programs. Here is a list of usage.
On larger programming environments, space for the stack is created in memory area called the application heap. When a procedure is called, space on the stack is needed to pass parameters, store the return address, and store local variables. Thus each invocation of a procedural call causes a block of memory from the stack to be reserved for that invocation. This block of memory is called a stack frame. Managing the data in the stack frame may be implemented using a separate pointer called the frame pointer.
The subroutine call is the first important use of the stack. When a program calls a subroutine using either the Branch to Subroutine (BSR) or the Jump to Subroutine (JSR) instruction, the location immediately following the BSR or JSR instruction must be remembered. Recalling this return address will allow the program to resume after the subroutine has been executed. When the BSR or JSR instruction is executed, the CPU will automatically push the return address onto the stack before setting the PC to the address of the subroutine called. A subroutine is exited by executing the Return from Subroutine (RTS) instruction. On executing the RTS instruction, the CPU will pop the return address off the stack and set it into the PC. Thus program execution resumes at the place after the subroutine was called.
Just as every push operation must be accompanied later by a pull operation, every call to a subroutine must be followed by the RTS instruction. Failure to do so would cause the stack to grow and the program will eventually crash. Never branch (BRA) or jump (JMP) out of a subroutine. This is one of the tenets of structured programming. (When the last instruction of a subroutine is a BSR or JSR followed by RTS, an optimization compiler may replace these with a BRA or JMP instruction.)
Subroutine calls may be nested indefinitely until the stack storage area is exhausted.
Variables may be declared to be either local or global. A local variable is one which is accessible only from within the owning subroutine. On the other hand, global variables are accessible by all subroutines. Programmers of high level languages such as C and Pascal are made aware of the importance of using local variables. On the HC08 and HC11, variables and labels are global. Great care must be taken by the programmer when accessing the same variable from different subroutines. Furthermore, all the hardware registers are also global entities and the programmer should document the usage of registers and whether they are altered by a subroutine.
Sometimes it is necessary to keep an accumulator unchanged even though it is used within the subroutine. In this case, using a local variable to store the contents of the accumulator is preferred. The stack is used for this purpose. In the following example, the subroutine called JOY begins by pushing the X, H and A registers onto the stack. Before returning, these must be pulled from the stack in reverse order. The accompanying diagram shows the stack and SP before and after the subroutine is called on the HCS08.
| JOY | PSHX | ;save H:X and A registers | ||
| PSHH | ||||
| PSHA | ||||
| PULA | ;restore A and H:X registers | |||
| PULH | ||||
| PULX | ||||
| RTS | ||||

In high level languages such as BASIC, C and Pascal, local storage and parameter
passing is implemented using the stack mechanism. With the HCS08, the Add Immediate
to the Stack Pointer instruction, AIS, is handy for allocating space from the
stack for local variables. For example, if five bytes of local storage is required,
| AIS #-5 |
will increase the stack frame by 5 bytes. Before the subroutine returns, the SP must be restore using:
| AIS #5 |
Global variables are assigned fixed memory locations in RAM. Hence global variables can be accessed from any program or procedure. While this may be convenient, it does not support the concept of modular programming. When a single byte needs to be passed to a procedure, the most convienent way is to pass the value via a register such as accumulator A. For a 16-bit parameter, the H:X register pair can be used to pass the value. When there are more input parameters than available hardware registers, space from the stack is used to pass parameter values. For example, an extra16-bit value can be pushed onto the stack via:
| PSHX | |||
| PSHH |
It is the responsibility of the calling procedure to restore the stack after the called subroutine has returned. This can be easily accomplished using a statement such as:
| AIS #2 |
When the data to be referenced is an array such as a vector or a character string, it is more efficient to pass the starting address of the array rather than all the elements of the array. Also, if a variable must be altered by the procedure, the address of the variable is passed rather than the value of the variable. In C, the address operator is &. Thus the statement &mydata passes the address of mydata. When the data is an array, passing &theArray[0] would have the same effect is just specifying theArray.
In C, you inform the compiler that the parameter is passed by reference by specifing a pointer using the * operator, e.g.
| void | myproc(int *x) | // pass by reference |
Compare this with the following:
| void | myproc(int x) | // pass by value |
When an errant program mismanages the stack or stack pointer, the SP will no longer point to the proper return address and the program will run astray and crash! The stack may also grow beyond the RAM space available. This can happen when there are too many nested interrupts or subroutine calls, along with subroutines requiring large numbers of local variables. In the case of the HC11 and HCS08 MCU, the stack begins at address $00FF and grows toward $0000. When the data on the stack collides with global data the consequence is usually a catastrophic failure.
Recursive and re-entrant programming rely heavily on usage of the stack. A recursive program is one which can call itself. The factorial function, f(n) = n! is computed as
f(n) = n × f(n-1) where f(0) is defined as 1
This is the classic example of a recursive process.
A re-entrant program is one which may be invoked in multiple instances at the same time. For example, suppose a division routine is implemented in software. The main program may be in the middle of a calculation involving a division when it gets interrupted. Now suppose the interrupt service routine also needs to perform a calculation using the same division subroutine. The interrupt service routine will produce the correct results. However, when the main program resumes its calculation following the interrupt, the results will only be correct if the division routine was designed to be re-entrant.